Team Viz
By Matan Banin, Senior Software Engineer at Viz.ai
Context: What Viz does and why speed matters
Imagine a neurologist getting a stroke alert at 2 a.m. A patient has just arrived in the ER, imaging is coming in, and every minute of uncertainty costs brain tissue.
That is the environment Viz.ai is built for. Our platform is used in real time across hospitals, where rapid access to imaging directly impacts treatment decisions and patient outcomes.
Viz.ai creates real‑time clinical intelligence that helps care teams act faster in time-sensitive situations like stroke, pulmonary embolism, and aortic disease. Imaging is often the first and most critical signal. When a study arrives, clinicians expect to open it and see clear images immediately, without waiting or wondering whether something is still loading.
Behind the scenes, imaging arrives as raw DICOM files organized hierarchically: a study contains one or more series, and each series can contain hundreds of DICOM files, where each DICOM represents a single image slice. In our pipeline, the series is the unit we convert, cache, and serve. To deliver a consistent, fast experience across web, desktop, and mobile clients, we convert the DICOM files within a series into a display‑ready image format that can be rendered everywhere the same way.
In that world, image availability isn’t a nice‑to‑have performance tweak. It directly shapes clinical trust and usability. If images take too long to load, even occasionally, speed stops being an optimization problem and becomes a product problem.
The original system
For years, we relied on S3 as a large cache for converted images. The idea was simple: convert once, store the result, and make repeat views fast.
Over time, this turned S3 into a long‑lived cache for image data.
The problem
Our S3 footprint started growing faster than we liked, eventually reaching the petabyte scale. The root cause was straightforward: we were storing too many converted images for too long.
Rethinking our storage strategy
When we looked at real usage patterns, one fact stood out: more than 90% of series were viewed within the first month after the scan. After that, access dropped off sharply.
We were effectively paying long‑term storage costs for data that was almost never opened.
That led to a clear decision: delete converted images after three months and regenerate them on demand if needed. The tradeoff was obvious: older series might experience a cold start when opened.
Constraints
By the time we fully understood the problem, one thing was clear: our options were constrained by reality.
This pipeline sat directly in the critical path of clinical workflows, so any change would be immediately visible to users. We couldn’t afford risky refactors or experimental designs.
- The system was already heavily used in production, which ruled out large rewrites.
- The user experience was synchronous, meaning images needed to be ready to view as soon as a clinician opened a study, without introducing visible delays.
- Tail latency mattered as much as the average, because even occasional slow loads were unacceptable – we were not willing to improve the mean at the expense of worst-case performance.
These constraints narrowed the solution space to changes that were incremental, predictable, and safe to ship.
The path we considered (and did not ship): trigger‑based pre‑generation
Our first instinct was to be proactive. We considered trigger‑based pre‑generation: when a patient received new imaging, or any other data update, we would re‑convert that patient’s prior studies so images stayed warm in S3.
At first glance, this resembled smart caching. In practice, it introduced significant inefficiency:
- Many studies would be regenerated and stored even though the patient was never viewed again
- Some patients would still fall outside the trigger logic and rely on on‑demand conversion
- The pipeline would steadily grow more complex as heuristics accumulated
The turning point
Instead of asking ourselves, “How do we predict what to cache?” We stepped back and reframed the problem.
What if conversion itself were fast and predictable enough that we didn’t need most of this pre‑generated data at all?
If on‑demand conversion could reliably complete in seconds, S3 could return to what it was best at: an object storage layer with short‑lived retention, rather than a long‑lived cache we were constantly trying to outsmart.
What we shipped: parallel conversion with a lightweight queue
We built a small proof‑of‑concept around a Python job queue that the team could adopt with minimal friction.
The core idea was to break image conversion into discrete jobs and process them with a pool of workers, instead of handling each study serially.
By pushing conversion work onto a queue and letting multiple workers pull from it concurrently, we could parallelize image generation in a controlled way, scaling throughput without turning the pipeline into a distributed systems exercise. This gave us much better latency characteristics while keeping the codebase simple and the control flow easy to reason about.
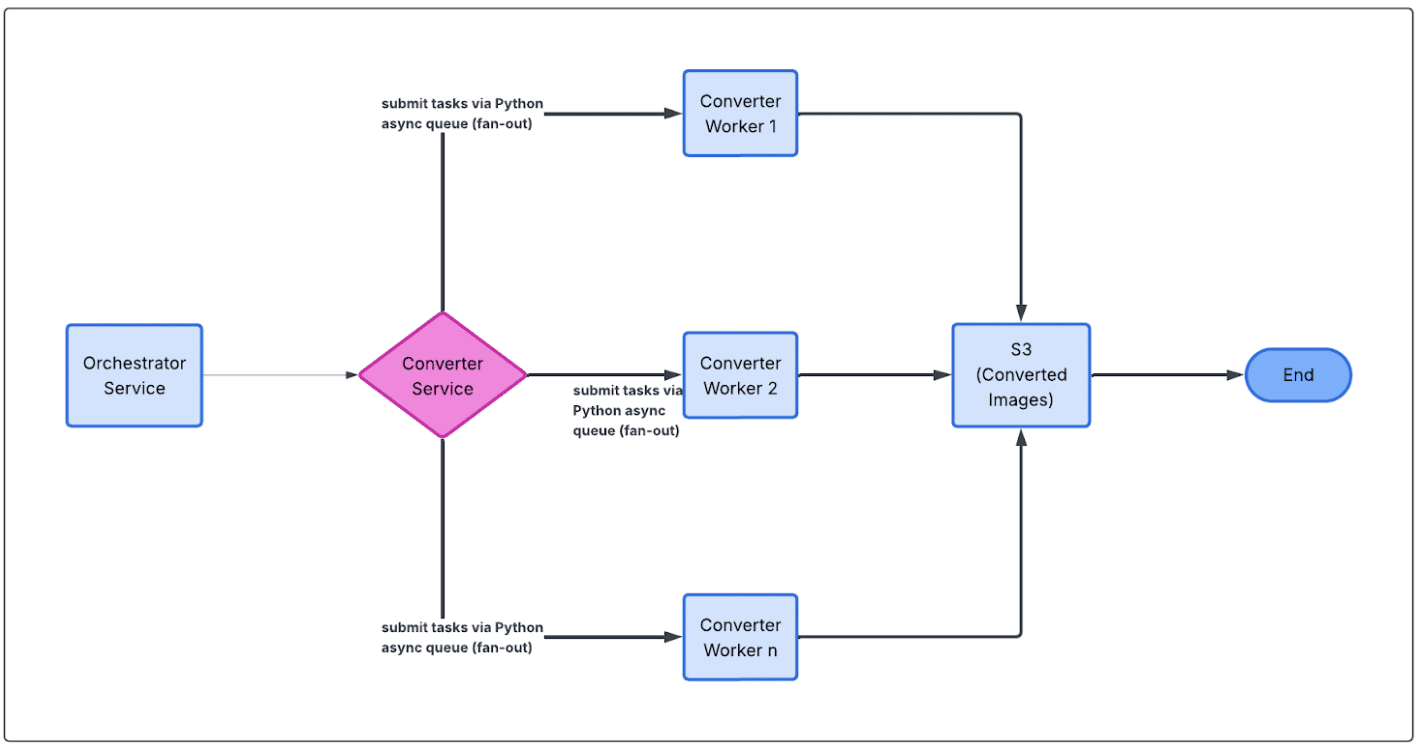
We deployed the new conversion path in shadow mode in production, before making any data deletion, compared results end‑to‑end, and monitored latency and error rates closely. Once it proved stable and fast enough for seamless user experience, we shipped it.
Results
The impact was immediate:
- Full study conversion (from hundreds individual DICOM files into a single display‑ready image set) dropped from ~20 seconds to ~3 seconds
- The 90th percentile stayed around ~5 seconds
For the vast majority of the workflows, this made the user experience feel almost immediate, including older studies that previously had noticeable delays.
With conversion now being both cost effective and predictable, we dramatically shortened the duration of converted images stored in S3.
Net result
We turned a constantly growing S3 footprint into 80%, stabilized infrastructure costs, improved the latency of ready‑to‑view imaging data, and ended up with a simpler, more maintainable architecture.
Takeaway
Sometimes the most effective optimization isn’t adding another clever layer – it’s questioning whether that layer needs to exist at all.
By focusing on making the core operation fast, predictable, and boring, we were able to simplify the system, lower costs, and improve user‑perceived performance at the same time.
The biggest gains came not from incremental tuning, but from stepping back and rethinking the problem.
If there’s one takeaway, it’s this: keep it simple, and don’t be afraid to challenge the default shape of a solution—even when it’s been working for years.
Learn more about how Viz.ai powers real-time care coordination and clinical decision-making across the healthcare ecosystem.